useEffect完全ガイド
2019 M03 9 • 🍱🍱 31 min read
Translated by readers into: Português do Brasil • 日本語 • 简体中文 • 繁體中文 • 한국어
Read the original • Improve this translation • View all translated posts
あなたは Hooks を使って複数のコンポーネントを書きました。ちょっとしたアプリも作ったことがあるでしょう。満足もしている。API にも慣れて、その過程でコツも掴んできました。しかも重複したロジックを転用できるよう Custom Hooks を作り、同僚に自慢して見たり。
でも useEffect を使う度、いまいちピンときません。class のライフサイクルとは似ているけど、何かが違う。そしていろんな疑問を抱き始めます。
- 🤔
componentDidMountをuseEffectで再現する方法は? - 🤔
useEffect内で正確に非同期処理を行う方法とは?[]ってなに? - 🤔 関数をエフェクトの依存関係として記すべき?
- 🤔 非同期処理の無限ループがたまに起こるのはなぜ?
- 🤔 古い state か props がエフェクト内にたまに入るのはなぜ?
私も Hooks を使い始めた時、同じような疑問を抱いてました。ドキュメントを書き始めた時も、まだ完璧に理解していませんでした。今回は、私がその後経験した アハモーメントを共有します。この記事を読むことによって、上記に挙げた質問を当たり前にわかるようになるでしょう。
答えが見えるようになるには、一歩下がって全体図を俯瞰して理解する必要があります。この記事の目的は箇条書きで答えを教えることではなく、 useEffect を完璧に理解していただくことです。習うことはそれほど多くはありません。それどころか、覚えていることを意識的に忘れることに注力していきます。
useEffect Hook を慣れている class のライフサイクルパラダイムと分離して初めて理解できました。
“覚えたことを全て忘れるのじゃ.” — Yoda

この記事は useEffect API をある程度理解していることが前提です
しかもすごい長文です。小さな本並みです。私が個人的に好むフォーマットなので、もし急ぎもしくはそこまで興味ない場合は、下に TLDR を書いたのでそちらを読んでください
もしこのようなディープダイブがしっくりこない場合は、他で説明されるのを待ったほうがいいかもしれません。React が 2013 年に出た時と同じように、人々が新たなメンタルモデルを理解して教えるのには時間がかかります。
—
TLDR(長すぎ、読んでない)
このセクションには全てを読みたくない人向けに簡潔に質問に答えています。理解できない部分があれば、下にスクロールしてその部分に関係あるところを読んでください。
この記事を全て読むのであれば遠慮なくこのセクションは飛ばしてください。最後にリンクを貼ります。
🤔 componentDidMountをuseEffectで再現する方法は?
useEffect(fn, []) でも再現できますが、全く同じという訳ではありません。 componentDidMount とは違い、props と state をキャプチャーします。なので、callback の中でも初期 props と state を参照できます。一番最新のなにかを参照したい場合は、ref として書けます。ですが大概は ref として書かなくてもいいようコードを構成する方法があります。覚えて欲しいことは、effects と componentDidMount や他のライフサイクルメソッドのメンタルモデルは別であることです。なので、それぞれのライフサイクルメソッドの代用を探そうとすると余計に混乱してしまいます。効率的になるためには「エフェクトで考える」必要があり、そのメンタルモデルはライフサイクルイベントに反応することではなく props や state の変化を DOM にシンクロさせる、という方に近いです。
🤔 useEffect 内で正確に非同期処理を行う方法とは? [] ってなに?
この記事を参考にしてみると良いでしょう。最後まで読むように!この記事ほど長くはありません。[]は、エフェクトは React のデータフローに携わる値をなに一つ使用していないので、一度だけ実行しても良いということを示していてます。ですが値が実際にエフェクト内で使用されている場合はバグの根源ともなります。依存関係を解消して正しく値を省くには複数のテクニック(主に useReducer と useCallback )を用いる必要があります。
🤔 関数をエフェクトの依存関係として記すべき?
推薦される方法としては props や state を必要としない関数はコンポーネント外にホイスティングして、エフェクトでしか使われない関数はエフェクト内に入れる方法です。しかしそのあとにもエフェクトがレンダースコープ内の関数を使うことがあるのであれば(props からの関数も含む)、 useCallback で関数が定義されている場所をラップしてそのプロセスをリピートします。なぜそれが大事かというと、関数は props や state を見ることができるので、React のデータフローに携わるからです。詳しくはFAQを参照してください。
🤔 非同期処理の無限ループがたまに起こるのはなぜ?
エフェクト内で非同期処理を依存関係を表す第二引数を与えないで実行すると起こります。第二引数がない場合、エフェクトは毎 render 時に走り、内部で state をセットしてると再度エフェクトをトリガーするからです。依存関係を表す第二引数に常に変わる値が入ってる場合でも無限ループは起きます。どれが問題の原因かは依存配列の中から値を一つ一つ削除していくことによって分かります。ですが、エフェクト内で使用してる値を依存配列から取り出したり(もしくは闇雲に [] を指定したり)するのは大概の場合、正しくない直し方です。その代わり、問題の根源から直していきましょう。例えば、関数などがこの問題を起こしがちで、エフェクト内に定義するか、ホイスティングするか useCallback でラップすると良いかもしれません。オブジェクトの再生成を阻止するために使われる useMemo も同じような用途で使えます。
🤔 古い state か props がエフェクト内にたまに入るのはなぜ?
エフェクトは必ず定義された render の props と state を見ることができます。この方法はバグを阻止するのに有効ですが、厄介と感じるケースもあります。その場合は、明確に値を mutable ref に保存すると良いでしょう(リンクされている記事の最後の方で説明してます)。もし古いレンダーからpropsやstateを参照して値が期待通りでないと考えたのなら、依存配列に何か入れ忘れている可能性があります。このlint ルールを使って、入れ忘れないように慣れましょう。使い始めて数日経てば、習慣になるはずです。こちらのFAQにも答えてるので参照してみてください。
この TLDR が役に立ったなら嬉しいです。そうでなければ、深入りしていきましょう。
それぞれの render は独自の props と state を保持している
エフェクトに関して話す前に、レンダーリングについて話す必要があります。
まず、ここにはカウンターがあります。ハイライトされた行を見てください:
function Counter() {
const [count, setCount] = useState(0);
return (
<div>
<p>You clicked {count} times</p> <button onClick={() => setCount(count + 1)}>Click me</button>
</div>
);
}どういうことでしょう? count は何とか props と state の変更を検知して自動的にアップデートされているのでしょうか?このメンタルモデルは React を学ぶ時の最初の直感としては役に立ちますが、実は正しくありません.
このサンプルでは、 count はただの数字です。 データバインディングやウォッチャーやプロキシなど手の込んだものではありません。古き良きただの数字です:
const count = 42;
// ...
<p>You clicked {count} times</p>;
// ...コンポーネントが一番初めに render する際、useState() から出力される count 変数は 0 です。setCount(1)を呼ぶと、React はコンポーネントは再度呼び出します。その際、 count は 1 となります:
// 初期 render 時
function Counter() {
const count = 0; // useState()の戻り値 // ...
<p>You clicked {count} times</p>;
// ...
}
// クリック後、関数が呼び出される
function Counter() {
const count = 1; // useState()の戻り値 // ...
<p>You clicked {count} times</p>;
// ...
}
// もう一度クリックすると、再度呼ばれる
function Counter() {
const count = 2; // useState()の戻り値 // ...
<p>You clicked {count} times</p>;
// ...
}state をアップデートする度、React はコンポーネント関数を呼び出します。それぞれの render 結果は定数として定義された counter state を見ることができます
したがって、この行は何も特別なデータバインディングをしてるわけではありません:
<p>You clicked {count} times</p>何をしてるかというと、render 結果に数字を組み込んでいるだけです。 この数字は React が提供しています。 setCount すると、React は違った count の値を使ってコンポーネントを呼び出しています。そして、render 結果にマッチするよう DOM をアップデートしてるのです。
ここで覚えていて欲しいのは count 定数は特定の render で時間の経過と共に変化するのではないということです。何が起こってるかというと、コンポーネント関数が呼び出されているのです - そして各 render はそれぞれその render に隔離された count値を 見る ことができるのです。
(このプロセスについてもっと深掘りしたい場合はReact as a UI Runtimeを参照してください。)
それぞれの render は独自のイベントハンドラを保持している
ここまでは順調ですね。ではイベントハンドラはどうでしょう?
この例を見てみてください。3 秒後に count の値を alert するイベントです:
function Counter() {
const [count, setCount] = useState(0);
function handleAlertClick() { setTimeout(() => { alert("You clicked on: " + count); }, 3000); }
return (
<div>
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>Click me</button>
<button onClick={handleAlertClick}>アラートを表示</button>
</div>
);}このような手順を踏んだとしましょう:
- count を 3 まで増やす
- “アラートを表示”を押下
- タイムアウトが発火する前に count を 5 まで増やす
アラートは何を表示するでしょう?アラートが表示される時の count state の 5 を表示するでしょうか?それとも押下した時の count state の 3 を表示するでしょうか?
この先ネタバレ
自分で一度再現してみてください!
もしこの挙動が意味をなさない場合は、もっと現実的な例を想像してみてください:受取人 ID を state に保持するチャットアプリと、送るボタンなど。この記事が理由を深掘りしていますが正解は 3 です。
アラートは押下時の state をキャプチャーします。
(5 を表示させるような実装をする方法はありますが、今回はデフォルトケースにフォーカスします。メンタルモデルを構築する際は最も容易な方法と避難ハッチを明確に区別する必要があります)
なぜこのような挙動をするのでしょう?
先ほど、 count は定数であり呼び出される関数ごとに保持していると議論しました。関数は何度も呼ばれる(render 毎に一度)が、その都度 count値は定数であり何かの値でセットされている(その render の state) というのは強調する価値があります。
これは React 特有の挙動ではありません。通常の関数も同じような挙動をします:
function sayHi(person) {
const name = person.name; setTimeout(() => {
alert("こんにちは, " + name);
}, 3000);
}
let someone = { name: "Dan" };
sayHi(someone);
someone = { name: "Yuzhi" };
sayHi(someone);
someone = { name: "Dominic" };
sayHi(someone);この例では、someone という変数が何度も再代入されてます(React 上のどこかと同じように、現在のコンポーネント state も代わり得ます。)ですが、sayHi 関数の中にはローカル name 定数が存在しており、その定数は特定の呼び出しとその引数で与えられた person に紐づいています name 定数はローカルなので、呼び出しごとに隔離されています!結果、タイムアウトが発火される時、それぞれの alert は 引数で与えられた name を覚えています。
上の例がなぜイベントハンドラが押下時の count を保持してるか説明してくれてます。同じような再代入の方針を採用した場合、それぞれの render は特定の count が見えています:
// 初期 render
function Counter() {
const count = 0; // Returned by useState() // ...
function handleAlertClick() {
setTimeout(() => {
alert("You clicked on: " + count);
}, 3000);
}
// ...
}
// 押下されると、コンポーネント関数が呼び出される
function Counter() {
const count = 1; // Returned by useState() // ...
function handleAlertClick() {
setTimeout(() => {
alert("You clicked on: " + count);
}, 3000);
}
// ...
}
// 再押下後、またコンポーネント関数が呼び出される
function Counter() {
const count = 2; // Returned by useState() // ...
function handleAlertClick() {
setTimeout(() => {
alert("You clicked on: " + count);
}, 3000);
}
// ...
}なので、実質的にはそれぞれの render は独自の handleAlertClick のバージョンを返しています。そしてそれぞれのバージョンは 独自の count を覚えています:
// 初期 render
function Counter() {
// ...
function handleAlertClick() {
setTimeout(() => {
alert("You clicked on: " + 0); }, 3000);
}
// ...
<button onClick={handleAlertClick} />; // 0 が入ってるバージョン // ...
}
// 押下されると、コンポーネント関数が呼び出される
function Counter() {
// ...
function handleAlertClick() {
setTimeout(() => {
alert("You clicked on: " + 1); }, 3000);
}
// ...
<button onClick={handleAlertClick} />; // 1 が入ってるバージョン // ...
}
// 再押下後、またコンポーネント関数が呼び出される
function Counter() {
// ...
function handleAlertClick() {
setTimeout(() => {
alert("You clicked on: " + 2); }, 3000);
}
// ...
<button onClick={handleAlertClick} />; // 2 が入ってるバージョン // ...
}この理由から、このデモの中でイベントハンドラは特定の render に属しており、押下するとその特定 render の中の counter state を使っているのが分かります。
特定の render の中では props と state は一生変わりません。 props と state が特定の render に隔離されていて同じということは、それを使用してる値(イベントハンドラも含む)もそうです。その値も特定の render に属しているのです。なので、イベントハンドラ内の非同期関数さえも同じ count の値を参照できます。
注記:上記の例で私は count の値を直指定しました。count の値は特定の render 内では変わり得ないので、この代入方法は安全です。定数で定義されていて数字です。オブジェクトなども同じように考えて問題ないと思いますが、それは mutate しないことが前提ならば、です。mutate する代わりに新しく作成されたオブジェクトでsetSomething(newObj)と呼び出すのは安全で、なぜかというと過去の render に属している state は損なわれていないからです。
それぞれの render は独自のエフェクトを保持している
この記事はエフェクトに関する記事のはずだったんですが、まだエフェクトのことについて話してませんでしたね!それでは今からそれを正しましょう。どうやら、エフェクトも他と何も変わりません。
このドキュメントにある例に戻ってみましょう:
function Counter() {
const [count, setCount] = useState(0);
useEffect(() => { document.title = `You clicked ${count} times`; });
return (
<div>
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>Click me</button>
</div>
);
}ここであなたに質問です。エフェクトはどのようにして最新の count state を読むと思いますか?
データバインディングやウォッチャーがエフェクト関数内で count の値をライブアップデートしてたり、もしくは count は mutable な変数であり React がうまい具合に最新の値をセットしてるからエフェクト内でも最新の値を参照できてるのだと思うかもしれない。
でもそれは違う。
count は定数であり、特定の render に属しているというのは先ほど説明した。ある render に紐づいているイベントハンドラは同じスコープ内に属している count の値を参照することができる。エフェクトも同じである。
「変化」しないエフェクト内で count 変数が変化している訳ではありません。 エフェクト関数そのもの が render ごとに異なっているのです
それぞれのバージョンは特定の render 内の count の値を参照することができます:
// 初期 render
function Counter() {
// ...
useEffect(
// 初期 render のエフェクト関数 () => { document.title = `You clicked ${0} times`; } );
// ...
}
// 押下されると、コンポーネント関数が呼び出される
function Counter() {
// ...
useEffect(
// 2回目の render のエフェクト関数 () => { document.title = `You clicked ${1} times`; } );
// ...
}
// 再押下後、またコンポーネント関数が呼び出される
function Counter() {
// ...
useEffect(
// 3回目の render のエフェクト関数 () => { document.title = `You clicked ${2} times`; } );
// ..
}React はあなたが与えたエフェクト関数を覚えており、DOMに変更が走ってブラウザに描画された後に実行されます。
概念的には一つのエフェクト(ドキュメントのタイトルを変える)なのですが、render されるごとに 別の関数 として表されています - そしてそれぞれのエフェクト関数は特定の render に属する props と state を参照することができます。
概念的に、エフェクトは render 結果 の一部であると想像してもらってもいいです。
完全に理解してるか確認するために、初期 render で何が起こるかおさらいしましょう:
- React: state が
0の時のUIをちょうだい。 -
あなたのコンポーネント:
- これが render 結果だよ:
<p>You clicked 0 times</p>. - それと、終わった後にこのエフェクトを実行するのを忘れないでね:
() => { document.title = 'You clicked 0 times' }.
- これが render 結果だよ:
- React: 了解。UIをアップデート中。ねぇブラウザ、DOMに色々追加してるよ
- ブラウザ: いいね。画面に描画したよ。
-
React: 了解。では今から与えられたエフェクトを実行するよ。
() => { document.title = 'You clicked 0 times' }を実行中
ではボタンをクリックしたらどうなるかもおさらいしておこう:
- あなたのコンポーネント: ねぇ React, state を
1にセットして。 - React: state が
1の時のUIをちょうだい。 -
あなたのコンポーネント:
- これが render 結果だよ:
<p>You clicked 1 times</p>. - それと、終わった後にこのエフェクトを実行するのを忘れないでね:
() => { document.title = 'You clicked 1 times' }.
- これが render 結果だよ:
- React: 了解。UIをアップデート中。ねぇブラウザ、DOMに色々追加してるよ
- ブラウザ: いいね。画面に描画したよ。
-
React: 了解。では今からこの特定の render に属するエフェクトを実行するよ。
() => { document.title = 'You clicked 1 times' }を実行中
それぞれの render は全てを保持している
エフェクトは render の後に実行され、概念的にはコンポーネント出力の一部であり、特定の render 内の state と props を参照できるというのは理解していただけたと思う
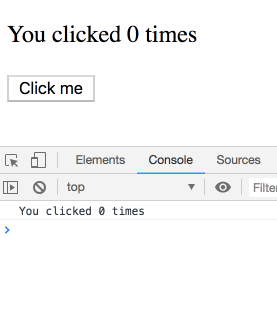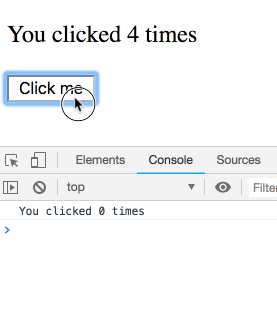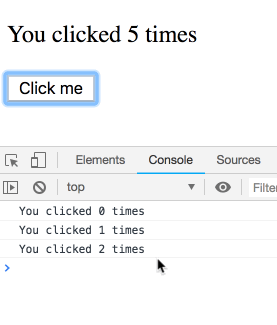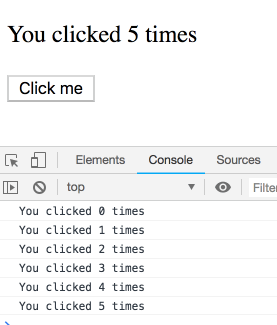
思考実験をしてみましょう。このコードについて考えます:
function Counter() {
const [count, setCount] = useState(0);
useEffect(() => { setTimeout(() => { console.log(`You clicked ${count} times`); }, 3000); });
return (
<div>
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>
Click me
</button>
</div>
);
}少し遅らせて複数回クリックすると、ログはどのような結果になるでしょうか?
この先ネタバレ
この質問はひっかけ問題であり直感的ではないと思われるでしょう。ですが違います!特定の render 内に属する count の値が順次出力されます。ご自分で一度試してみてください
「当たり前じゃん!これ以外どのような挙動するの?」と思われるでしょう。
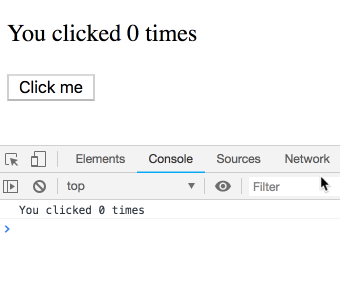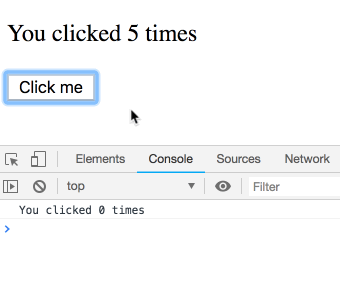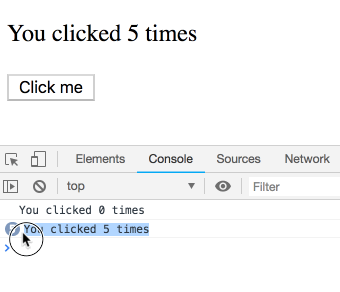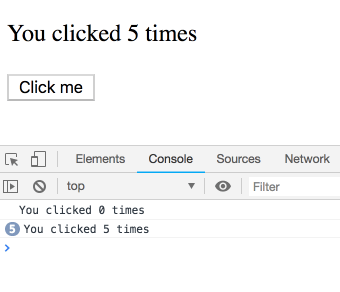
class コンポーネントの this.state は、このような挙動をしませんよ。このコードが同じような挙動をすると思うのはよくある勘違いです:
componentDidUpdate() {
setTimeout(() => {
console.log(`You clicked ${this.state.count} times`);
}, 3000);
}this.state.count は特定の render に属する値ではなく、常に最新の count の値を参照します。なので、代わりに 5 が順番に表示されます:
Hooks は JavaScript のクロージャに頼りきっているのに、class の実装がクロージャとよく関連づけられるタイムアウト内に違う値が入る不思議な現象に苦しむなんて、皮肉ですね。なぜかというと、混同の元は mutation であり、(React は this.state を mutate して最新の値を指すようにしてる)クロージャ自体ではありません。
クロージャは、クローズする値が変わらない場合にとても役に立ちます。基本的に定数を参照するということなので、何も難しく考える必要がありません そして先ほどにも述べたように、 props と state は特定の render 内では一生変わりません。ちなみに、class のバージョンは直すことができます… クロージャを使って。
流れに逆らう
この時点で明示的に重要なことが言えます。それは、コンポーネント render 内の全ての関数(コンポーネント内で定義されてるイベントハンドラ、エフェクト、タイムアウト、APIの呼び出しなどを含む)は定義されてる特定の render 内の props と state をキャプチャーします。
なので、この二つの例は同様の挙動をします:
function Example(props) {
useEffect(() => {
setTimeout(() => {
console.log(props.counter); }, 1000);
});
// ...
}function Example(props) {
const counter = props.counter; useEffect(() => {
setTimeout(() => {
console.log(counter); }, 1000);
});
// ...
}props か state を「早めに」コンポーネント内で呼ぼうが呼ばまいが関係ありません。 なぜなら変わらないからです!一つの render 内のスコープでは、 props と state は変わりません。(分割代入するとさらに分かりやすいです。)
ですが、特定の render 内の値ではなく最新の値をエフェクト内で定義されてる callback内で 使いたい 場合もありますよね。これを成し遂げる一番簡単な方法は、この記事の最後のセクションにも説明されてるように、 refs を使うことです。
ですが、 未来の props や state を読みたいということは React の流れに逆らっているというのを用心してください。間違ってはいません(そして時々必要)が、パラダイムから抜け出すという意味であまり 綺麗には見えないかもしれません。これは意図した仕様で、なぜかというとどのコードが脆く、タイミングに頼っているか洗い出しハイライトしてくれる役割を担っています。classes ではこの現象が起きてもあまり明らかにはされません。
こちらが class の動作と同じような動きをする counter の例です:
function Example() {
const [count, setCount] = useState(0);
const latestCount = useRef(count);
useEffect(() => {
// mutable な最新の値をセットする latestCount.current = count; setTimeout(() => {
// mutable な最新の値を読む console.log(`You clicked ${latestCount.current} times`); }, 3000);
});
// ...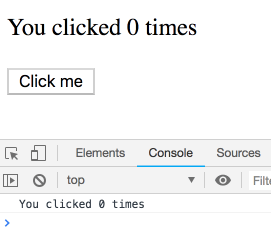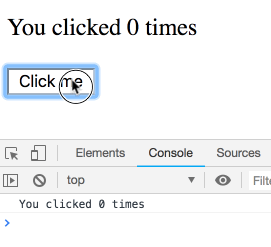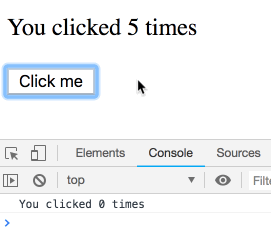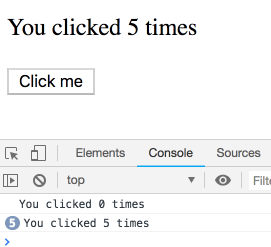
React で何かを mutate するという行為は風変わりに見えるかもしれません。ですが、まさにこの方法で React は classes の this.state を reassign しています。特定の render でキャプチャーされた props と state とは違い、 latestCount.current は特定の callback の値を変わらずに参照できる、とは限りません。定義上は、いつでも mutate 可能なのです。このような理由からデフォルトではなく、自分から選んで使う必要があります。
では Cleanup はどうでしょう?
ドキュメントで説明されているように、一部のエフェクトは cleanup phase があるかもしれません。サブスクリプションなど、エフェクトを元に戻す役割を果たします。
このコードを見てください:
useEffect(() => {
ChatAPI.subscribeToFriendStatus(props.id, handleStatusChange);
return () => {
ChatAPI.unsubscribeFromFriendStatus(props.id, handleStatusChange);
};
});初期 render 時には props は {id: 10} として、2回目の render 時は {id: 20} になるとしましょう。このようなことが起きると思われるでしょう:
- React が
{id: 10}のエフェクトを cleanup する。 - React が
{id: 20}の UI を render する。 - React が
{id: 20}のエフェクトを実行する。
(ちょっと違います。)
このメンタルモデルでは、re-render 前に cleanup は実行されるので 古い props が見えていると思われるでしょう。そして、新しいエフェクトは re-render 後に実行されるので最新の props が見えていると。ですがこれは class のライフサイクルのメンタルモデルに基づいていて、ここでは 正確ではありません。 理由を見ていきましょう。
React はブラウザが描画した後に初めてエフェクトを実行します。この方法だとスクリーンアップデートをブロックすることがないので、アプリを早くしてくれます。それと同様で、エフェクトの cleanup も遅れて実行されます。 前のエフェクトは新しい props で re-render されてから cleanup されます:
- React が
{id: 20}の UI を render する。 - ブラウザが描画する。
{id: 20}の時の UI が画面に表示される。 - React が
{id: 10}のエフェクトを cleanup する。 - React が
{id: 20}のエフェクトを実行する。
でもどうやって前のエフェクトの cleanup は props が {id: 20} に変わって re-render された後に実行されてるのに、古い {id: 10} の props が見えてるの?と思われるでしょう。
前にも遭遇した問題ですね… 🤔

前のセクションから引用します:
コンポーネント render 内の全ての関数(コンポーネント内で定義されてるイベントハンドラ、エフェクト、タイムアウト、APIの呼び出しなどを含む)は定義されてる特定の render 内の props と state をキャプチャーします。
これで答えは明確ですね!エフェクトの cleanup はどういう意味であろうと最新の値を読んだりしません。エフェクトが定義されている特定の render 内の props を読んでいるのです:
// 初期 render 時、 props は {id: 10}
function Example() {
// ...
useEffect(
// 初期 render のエフェクト関数
() => {
ChatAPI.subscribeToFriendStatus(10, handleStatusChange);
// 初期 render のエフェクトを cleanup return () => { ChatAPI.unsubscribeFromFriendStatus(10, handleStatusChange); }; }
);
// ...
}
// 2回目の render 時、props は {id: 20}
function Example() {
// ...
useEffect(
// 2回目の render のエフェクト関数
() => {
ChatAPI.subscribeToFriendStatus(20, handleStatusChange);
// 2回目の render のエフェクトを cleanup
return () => {
ChatAPI.unsubscribeFromFriendStatus(20, handleStatusChange);
};
}
);
// ...
}帝国は滅び遺灰に変わり、太陽の外層は削ぎ落とされ白色矮星に変形し、最後の文明は終わりを迎えます。ですが誰も初期 render の cleanup を定義された特定の render 内の {id: 10} 以外のものを cleanup させることはできません。
これらの理由により React は描画後エフェクトを実行するのです - デフォルトであなたのアプリを早くするために。古い props はコードが必要な時のために存在はしています。
ライフサイクルではなく、シンクロ
React の何が好きかっていうと、初期 render の結果記述とアップデートが統一されているところです。これによりプログラムの均質化を防ぐことができます。
このようなコンポーネントがあるとしましょう:
function Greeting({ name }) {
return (
<h1 className="Greeting">
Hello, {name}
</h1>
);
}<Greeting name="Dan" /> を render して後に <Greeting name="Yuzhi" > に変えようが、直接 <Greeting name="Yuzhi" /> を render しようが関係ありません。最終的には、どちらのケースでも “Hello, Yuzhi” と出力されます。
よく人は「すべては過程だ。結果ではない」と言います。ですが、 React の場合は逆です。全ては結果であり、過程ではありません。 これが jQuery の $.addClass と $.removeClass(過程)などの呼び出しと React であるべき CSS クラスを定義する行為(結果)の違いです。
React は現在の props と state に応じて DOM をシンクロします。 render 時は mount や update に区別はありません。
エフェクトを同じように考えるのが正解でしょう。useEffect は、React tree 以外のものを props と state に応じて シンクロ してくれます。
function Greeting({ name }) {
useEffect(() => { document.title = 'Hello, ' + name; }); return (
<h1 className="Greeting">
Hello, {name}
</h1>
);
}これは、mount/update/unmount のメンタルモデルとは微妙に異なります。 これはしっかり理解しましょう。初期 render か否かで違う挙動をするエフェクトを書こうとしてる場合は、React の流れに逆らっています! もし、結果が 過程 に頼ってしまっている場合は、シンクロに失敗しています。
props A, B, と C と順に render しようが C でいきなり render しようが関係ないはずです。多少違いはあるかもしれませんが(例えば data を fetch している間など)、最終結果は同じであるはずです。
それでも、全てのエフェクトを render 毎に実行させるのは効率的ではないかもしれません(そして場合によっては無限ループにも繋がります)。
どうしたら解決できるでしょうか?
React にエフェクトを比較することを教える
この教訓はもう既に DOM 操作で習っています。React は DOM がアップデートされた箇所だけ認識して、全てを触らずに変更点だけアップデートします。
<h1 className="Greeting">
Hello, Dan
</h1>を
<h1 className="Greeting">
Hello, Yuzhi
</h1>へアップデートするとします。この時、 React は二つのオブジェクトを受け取ります:
const oldProps = {className: 'Greeting', children: 'Hello, Dan'};
const newProps = {className: 'Greeting', children: 'Hello, Yuzhi'};それぞれの props を比べて、 children は変更しているので DOM アップデートは必要ですが className は変わっていないので、このような処理をします:
domNode.innerText = 'Hello, Yuzhi';
// domNode.classNameは触る必要なしこのような処理をエフェクトでもできるでしょうか?エフェクトを実行する必要がない場合は実行しない、とかできたらいいですよね。
例えば、state の変更によりコンポーネントが再 render するかもしれません:
function Greeting({ name }) {
const [counter, setCounter] = useState(0);
useEffect(() => {
document.title = 'Hello, ' + name;
});
return (
<h1 className="Greeting">
Hello, {name}
<button onClick={() => setCounter(count + 1)}> Increment </button> </h1>
);
}ですが、我々のエフェクトは counter の state を使用していません。 このエフェクトは、document.title を name prop でシンクロさせています。ですが、 name prop は変わりません。 なので、 document.title を counter が変わるごとにリアサインするのは、効率的とは言えません。
React は単純に DOM の違いを勝手に検知できるようにエフェクトも違いを検知できないの?と思いますよね。
let oldEffect = () => { document.title = 'Hello, Dan'; };
let newEffect = () => { document.title = 'Hello, Dan'; };
// React はこの二つの関数が同じことをしているということが分かるのか?実はできません。React は一度関数を呼ばないと、その関数が何をしているか推測することはできません。
なので、もし不必要なエフェクトを再実行したくない場合は、依存配列(deps とも言われる)というものを第 2 引数として useEffect に渡します:
useEffect(() => {
document.title = 'Hello, ' + name;
}, [name]); // Our deps「関数の戻り値が分からないのは知ってるけど、render scope 内で name しか使ってないことを約束するよ」と React に言ってるみたいなものです。
もし配列内のそれぞれの値が現在と一つ前のエフェクト実行時と同じであれば、シンクロするものがないので React はエフェクトをスキップします:
const oldEffect = () => { document.title = 'Hello, Dan'; };
const oldDeps = ['Dan'];
const newEffect = () => { document.title = 'Hello, Dan'; };
const newDeps = ['Dan'];
// React は関数の戻り値を分かることはできないが、deps を比べることはできる。
// この例では、 deps は同じであるため新しいエフェクトを実行せずに済む。もし一つでも deps の値が render ごとに違ったら、エフェクトはスキップされてはならないというのが分かります。シンクロタイムだ!
React に依存関係の嘘をついてはならない
React に嘘をつくと、後に悪影響を与えることになる。直感的には理屈に合うのだが、class のメンタルモデルを流用して useEffect を使う人たちはたくさん見てきました(そして自分も最初は同じでした!)。
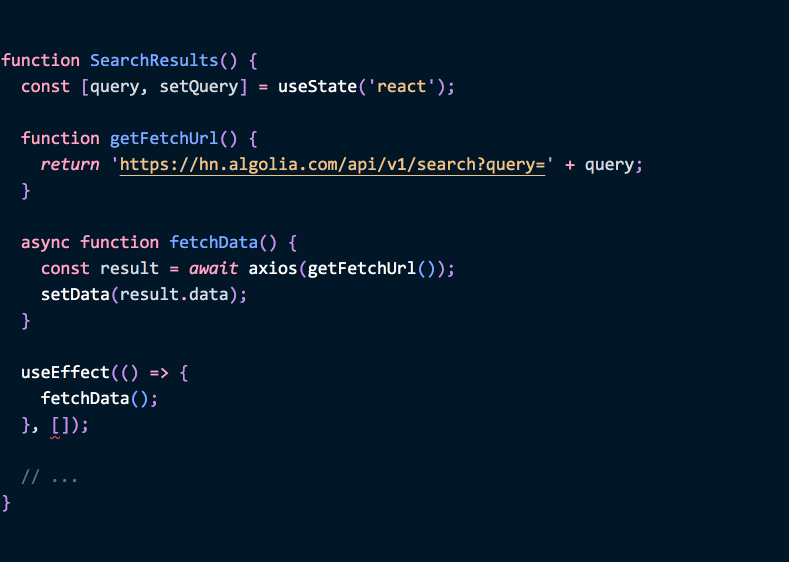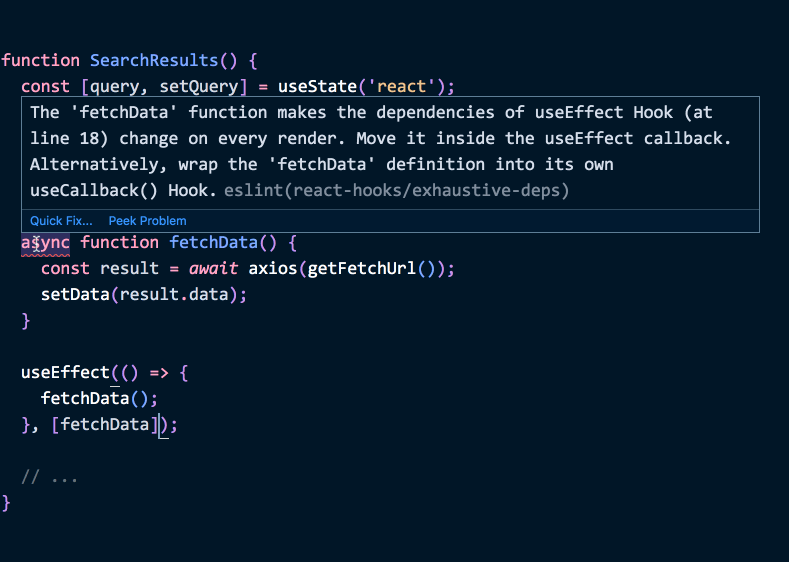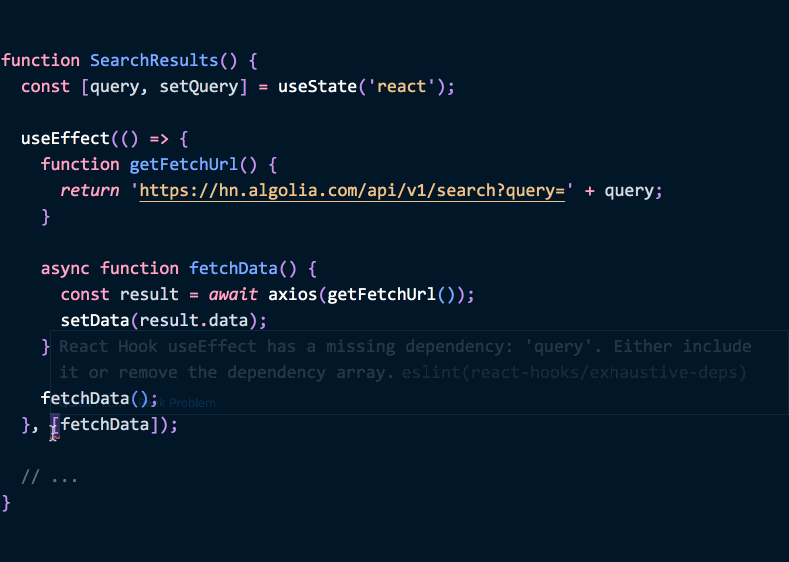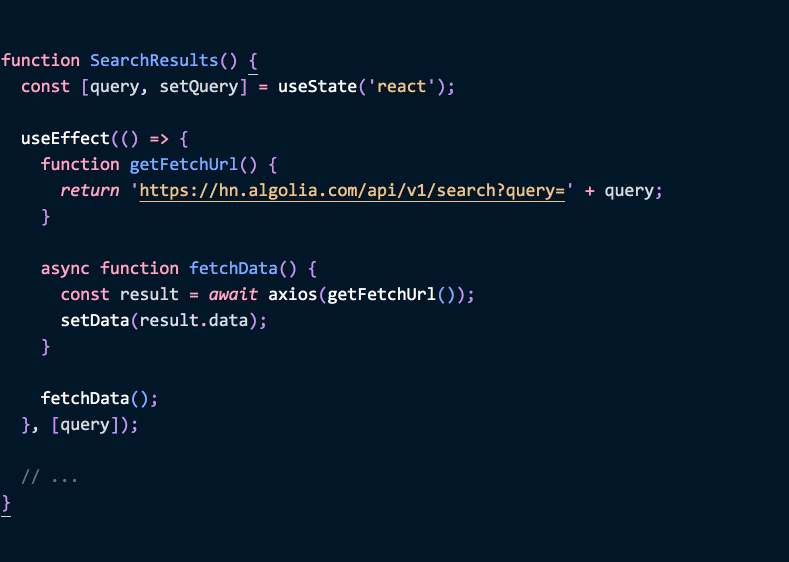
function SearchResults() {
async function fetchData() {
// ...
}
useEffect(() => {
fetchData();
}, []); // これは適してるのでしょうか?必ずしもそうであるとは限りません - もっと良い方法があります。
// ...
}(Hooks の FAQ に詳しく方法を書いています。この例にはまた後で戻ってきます)
「でも、 mount 時だけに実行したい!」と思うかもしれません。とりあえず今はこれだけ覚えてください: deps を指定する場合、 コンポーネント内の値がありエフェクトでも使われてる場合は、全て記述してください。 それはコンポーネント内の props, state, そして関数も含みます。
ですが稀に問題を引き起こす場合もあります。例えば、無限 refetch ループに出くわしたり、ソケットが何度も作られたり。 これらの解決策は対象 deps を配列内から削除することではありません。 最善の解決策は後ほどお見せします。
ですが解決策を見る前に、なぜ起こるのか探っていきましょう。
依存関係に嘘をつくと何が起こるのか
もしエフェクト内で使われてる全ての値が deps に含まれていると、 React はいつエフェクトを再実行するか分かります:
useEffect(() => {
document.title = 'Hello, ' + name;
}, [name]);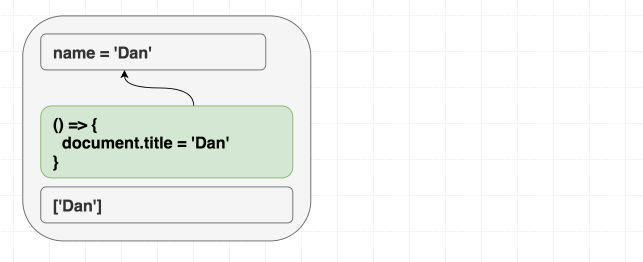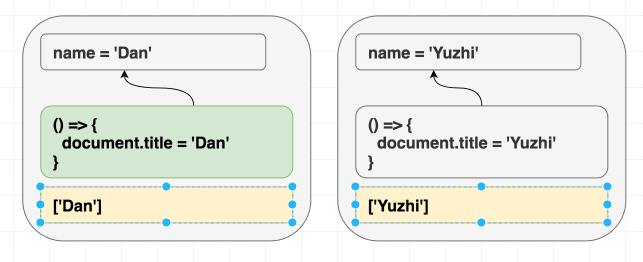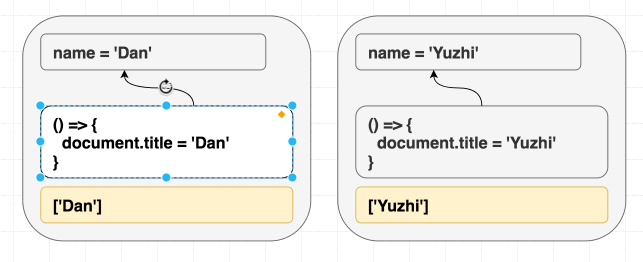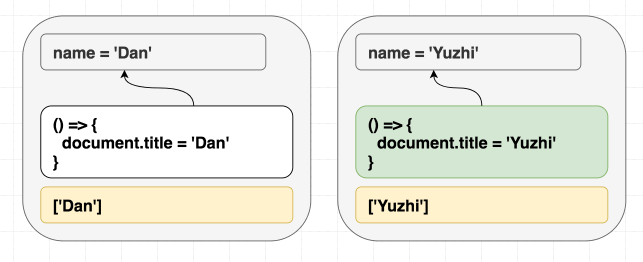
(依存する値が render 後に異なるため、エフェクトを再実行します。)
ですが依存配列を [] とした場合、最新のエフェクトは実行されません:
useEffect(() => {
document.title = 'Hello, ' + name;
}, []); // 間違い: name が deps に入ってません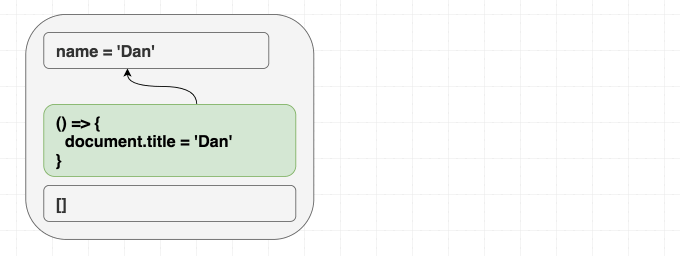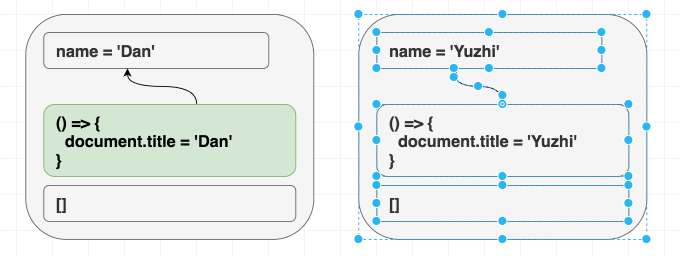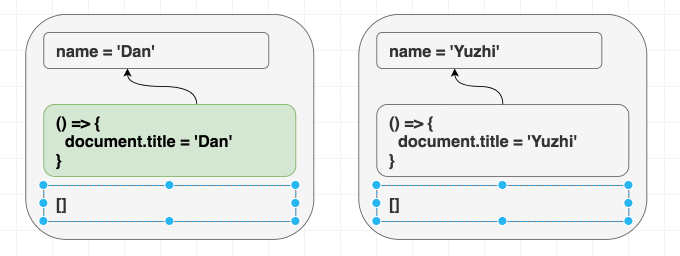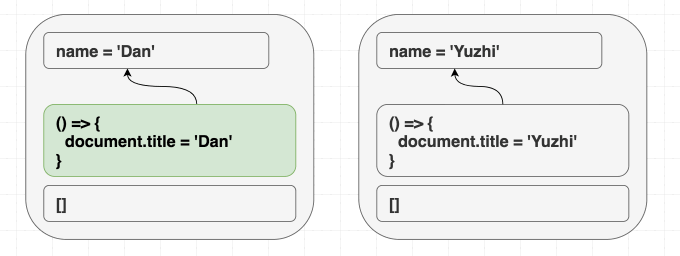
(依存する値が render 後も同じなので、エフェクトをスキップします。)
ぱっと見だとこの問題は当たり前だと思うかもしれません。ですが、直感的に class での解決策が思い浮かんで混乱することもあります。
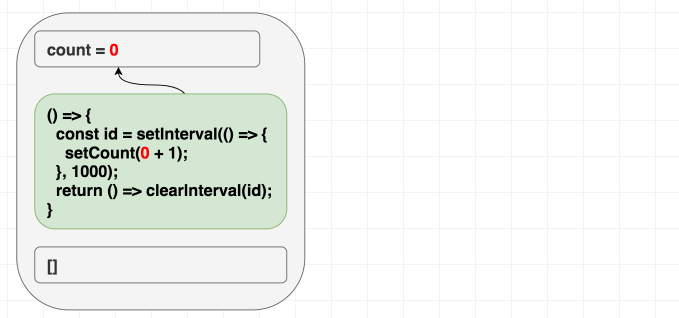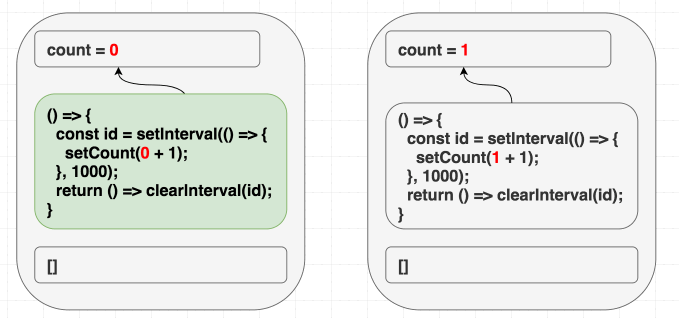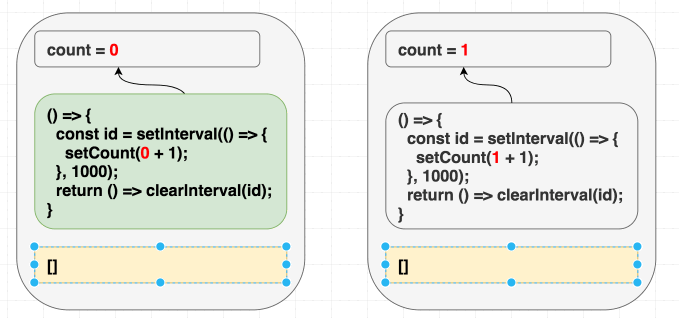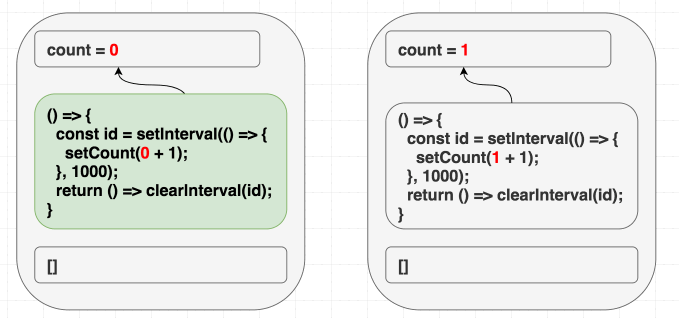
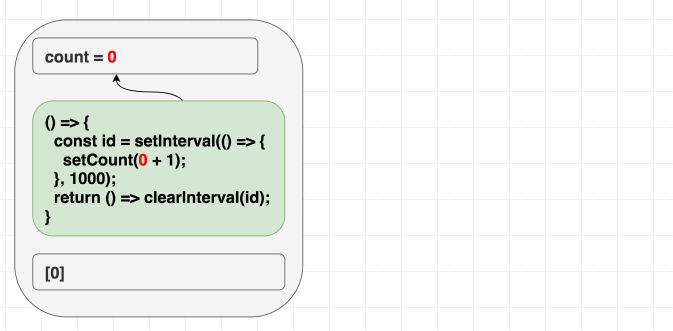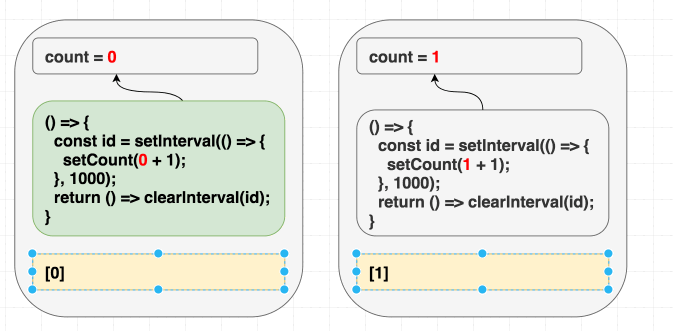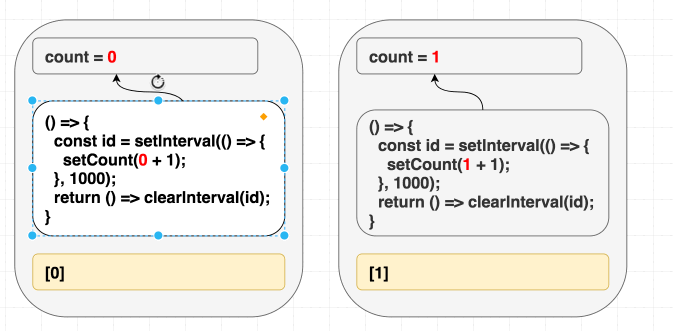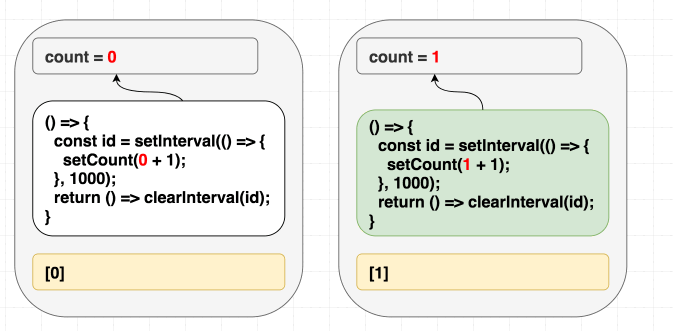
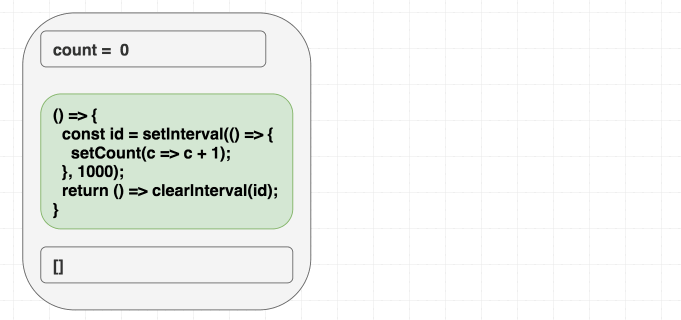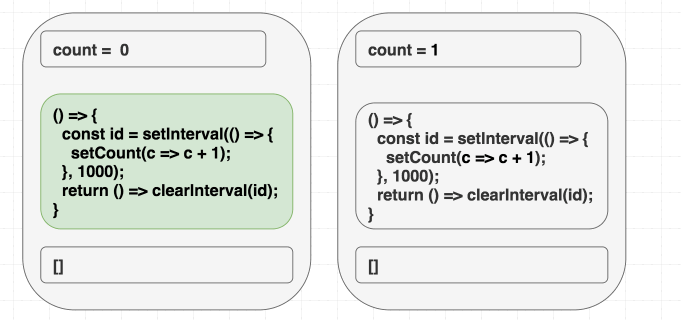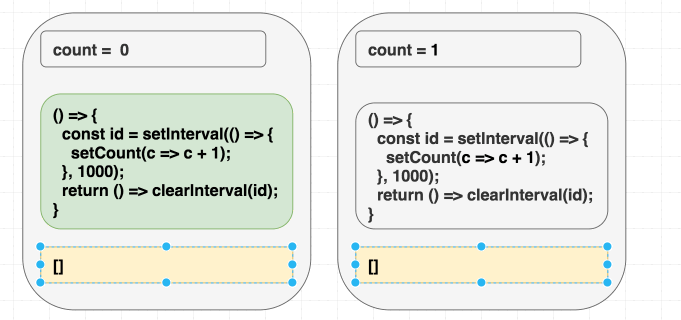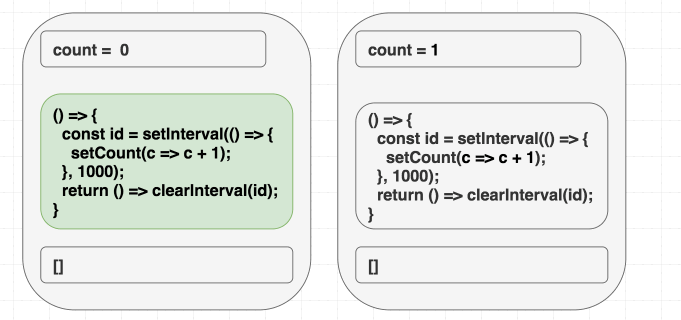
例えば、毎秒 1 づつ increment していくカウンターコンポーネントを作成してるとしましょう。 class のメンタルモデルでは setInterval を一度だけセットして、それを終わり次第 destroy するのが直感的に思い浮かぶでしょう。こちらが実際に実装した例です。このコードを useEffect のメンタルモデルに置き換えると、直感的に [] を deps に与えてしまいます。なぜなら一度だけ実行したいからでしょ?
function Counter() {
const [count, setCount] = useState(0);
useEffect(() => {
const id = setInterval(() => {
setCount(count + 1);
}, 1000);
return () => clearInterval(id);
}, []);
return <h1>{count}</h1>;
}ですが、この例だと一度しか increment しません 。あれ?
あなたのメンタルモデルが「依存配列は再実行したいタイミングを指定させてくれる」だと、この例であなたは自分の存在意義を問うことになるでしょう。intervalなので一度だけ実行 したい のに、何が問題を引き起こしているのでしょうか?
ですが、dependencies は React に対してエフェクトが render scope 内で使う 全て の値に対するヒントであるというのを知っていると、理にかなってます。エフェクト内で count を使っているのに、依存配列に [] と指定することで嘘をつきました。バグを引き起こすのも時間の問題です。
初期 render 時は、 count は 0 です。なので、 setCount(count + 1) は初期 render のエフェクトでは setCount(0 + 1) という意味です。 [] を指定してるので再実行はされません。なので、 setCount(0 + 1) を毎秒呼び続けているのです:
// 初期 render 時は state = 0
function Counter() {
// ...
useEffect(
// 初期 render のエフェクト
() => {
const id = setInterval(() => {
setCount(0 + 1); // Always setCount(1) }, 1000);
return () => clearInterval(id);
},
[] // 初期以降二度と実行されない );
// ...
}
// その後全ての render では state = 1
function Counter() {
// ...
useEffect(
// このエフェクトは常に無視される。 // なぜなら、空配列と嘘をついたからである。 () => {
const id = setInterval(() => {
setCount(1 + 1);
}, 1000);
return () => clearInterval(id);
},
[]
);
// ...
}コンポーネント内の値に依存しているのに、 エフェクトはどの値にも依存していないと嘘をつきました!
このエフェクトは、コンポーネント内にはあるがエフェクト内にはない count の値を使っています:
const count = // ...
useEffect(() => {
const id = setInterval(() => {
setCount(count + 1); }, 1000);
return () => clearInterval(id);
}, []);なので、 依存配列に [] と指定するとバグを起こします。 React は依存配列の中身の値を比較し、エフェクトをスキップします:
(配列内の値が同じなので、エフェクトをスキップします。)
このような難題は理解に苦しみます。なので、エフェクト内の依存関係については常に正直であることをルール化するのをオススメします。もしチーム内で徹底する場合は、lint rule を提供しています。
依存関係に正直になる二つの方法
依存関係に正直なる方法として、二つの方針があります。一般的には最初の策で始めて、二個目の策は必要であれば適用してください。
コンポーネント内で定義されていて、エフェクト内で使われている全ての値を依存配列の中に入れてください。それが一つ目の方法です。 count を deps として入れてみましょう:
useEffect(() => {
const id = setInterval(() => {
setCount(count + 1); }, 1000);
return () => clearInterval(id);
}, [count]);これで、依存配列は正しくなりました。最適な 方法とは言えませんが、これが一番初めに直すべきことです。これで、 count の値が変わればエフェクトは再実行されて、 setCount(count + 1) はその render に定義されている count を正しく参照します。
// 初期 render 時、state = 0
function Counter() {
// ...
useEffect(
// 初期 render 時のエフェクト
() => {
const id = setInterval(() => {
setCount(0 + 1); // setCount(count + 1) }, 1000);
return () => clearInterval(id);
},
[0] // [count] );
// ...
}
// 2回目の render 時、state = 1
function Counter() {
// ...
useEffect(
// 2回目の render 時のエフェクト
() => {
const id = setInterval(() => {
setCount(1 + 1); // setCount(count + 1) }, 1000);
return () => clearInterval(id);
},
[1] // [count] );
// ...
}こうすることによってこの問題は解決されますが、 count が変わる度に interval が clear されてしまいます。これは望ましくないかもしれません:
(依存配列の中の値が違うので、エフェクトを再実行します。)
よく変わる値をそもそも必要としないエフェクトにコードを書き換えるというのが、二つ目の方法です。 依存関係について嘘はつきたくはありません - なので、エフェクト内の依存する値を減らすのです。
依存配列の中身を減らす方法をみていきましょう。
自律的なエフェクトを作る
count の値をエフェクトから出したいとしましょう:
useEffect(() => {
const id = setInterval(() => {
setCount(count + 1); }, 1000);
return () => clearInterval(id);
}, [count]);そうするには、まずなぜ count が必要なのか考えましょう。 setCount の中でしか使ってないように見えます。この場合だと、 count をスコープ内に含める必要は実はありません。前の state に基づいて state をアップデートしたい場合は、setState の関数型の更新を使えます:
useEffect(() => {
const id = setInterval(() => {
setCount(c => c + 1); }, 1000);
return () => clearInterval(id);
}, []);このようなケースを僕は「不正な依存」と呼んでいます。 確かに、 setCount(count + 1) とエフェクト内に書いたので count は依存配列内に必要な値です。ですが、 count + 1 に形成して React に送り返す事にしか count を使っていません。しかし、 React は現在の count の値をもう知っています。 今の値など関係なく、やることは React に state を increment するということを伝えるだけです。
setCount(c => c + 1) はまさにそれをします。 React に state をどのように変更すべきか指示を送っていると考えてください。アップデートをバッチ処理したい時など、他のケースでも関数型の更新は役に立ちます。
我々は何も不正なことはしていません。実際に依存配列から抜き出すことができるように実装しただけです。我々のエフェクトはもう render scope 内の counter の値を参照することはなくなりました:
{kind=link}
(依存配列の中の値が同じなので、エフェクトをスキップします。)
一度試してみてください。
エフェクトは一度しか実行されないのにも関わらず、初期 render に紐づいている interval の callback は c => c + 1 の指示を interval が発火する度に送ることが容易にできます。現在の counter の state を知る必要がなくなったのです。なぜなら、 React がもう知っているから。
関数アップデートと Google Docs
シンクロがエフェクトのメンタルモデルであると話したことを覚えていますか?シンクロの興味深い点として、システム間の情報伝達はなるべくそれぞれの状態と隔離されて行われるべきというのがあります。例えば、Google Docs でドキュメントを編集する際、全てのページをサーバーに送っているわけではありません。それは非効率であるからです。代わりに、ユーザーの動きを表したデータを送るのです。
我々のケースは少し違いますが、エフェクトの挙動はほぼ同じような原理です。必要最低限の情報をエフェクト内からコンポーネントに送ることが最適化の助けになります。 setCount(c => c + 1) のような関数アップデート型は、 setCount(count + 1) のように不必要な state と紐づいていないので伝達する情報量は圧倒的に少ないのが分かります。アクションを表現しているだけです(増加)。必要最低限の state を見出すのは React 自体を理解するのに重要で、これはそれのアップデート版と言えるでしょう。
結果より意図を符号化する行為は、Google Docs が多人数編集を可能とした方法と似ています。少し言い過ぎかもしれませんが、関数アップデートも React の上では同じような挙動をしています。複数のソース(イベントハンドラやエフェクトのサブスクリプションなど)からのアップデートが確実にバッチ適用されて、かつ予測的であるのを保証してくれます。
ですが、setCount(c => c + 1) もそこまで効率的とは言えないです。 できることが制限されているのと、少し不自然でもあります。例えば、変数が二つ定義されていてそれぞれがお互いの値に依存していたり、 prop の値から次の state を計算する必要がある場合はうまくいきません。ですが、幸いにも setCount(c => c + 1) はもっとパワフルな代替手段があるのです。それが useReducer です。
アクションからアップデートを分離する
先ほどの例を少し変えて、count と step の二つの state 変数を持っていることにしましょう。 step のインプットによって我々の interval は count の値を増やしていきます:
function Counter() {
const [count, setCount] = useState(0);
const [step, setStep] = useState(1);
useEffect(() => {
const id = setInterval(() => {
setCount(c => c + step); }, 1000);
return () => clearInterval(id);
}, [step]);
return (
<>
<h1>{count}</h1>
<input value={step} onChange={e => setStep(Number(e.target.value))} />
</>
);
}(デモはこちら。)
私たちは何も不正なことはしていません。 step をエフェクト内で使い始めたため、依存配列の中に足しました。なので、このコードはちゃんと実行されます。
今の仕様のままだと、 step は依存配列の中にあるので step が変われば interval はリスタートされてしまいます。そしてほとんどの場合、それは求めている挙動かもしれません。エフェクトをクリアして新しい interval を立てるのは問題ありませんし、正当な理由なくそれを拒む必要はありません。
ですが、 step が変わっても interval の時間を止めたくないとしましょう。どうしたら step を依存配列から取り除けるでしょうか?
もし変数がもう一つの変数の現在値に依存してしまっている場合は、それらを useReducer に置き換えた方がいいでしょう。
もし setSomething(something => ...) のような書き方をしているのであれば、 代わりに reducer を使うことを考えた方がいいでしょう。 reducer はコンポーネント内で起こったアクションとそのレスポンスに応じて state がアップデートされる関係性を分離してくれます。
依存配列の中の step を dispatch に変えてみましょう:
const [state, dispatch] = useReducer(reducer, initialState);const { count, step } = state;
useEffect(() => {
const id = setInterval(() => {
dispatch({ type: 'tick' }); // etCount(c => c + step) の代わり; }, 1000);
return () => clearInterval(id);
}, [dispatch]);(デモはこちら。)
なぜこちらの方法が良いのか疑問に思われるでしょう。React は dispatch 関数がコンポーネントライフタイムの間は常に constant であることを保証してくれます。なので、上記の例では interval に再サブスクライブする必要がありません。
問題を解決しました!
(dispatch 、 setState や useRef などのコンテナ変数は依存配列に入れる必要はありません。なぜかと言うと、 static であるということは React が保証しているからです。ですが入れることに関してはなんら問題はありません。)
エフェクト内で state を読む代わりに、 何が起こったかの情報を含んだアクションを dispatch します。こうすることによって、 step 変数とエフェクトを分離させることができます。エフェクトはどのようにアップデートするかは興味を持たず、何が起こったかだけ教えてくれます。そして reducer はそのロジックを一元化してくれます:
const initialState = {
count: 0,
step: 1,
};
function reducer(state, action) {
const { count, step } = state;
if (action.type === 'tick') { return { count: count + step, step }; } else if (action.type === 'step') {
return { count, step: action.step };
} else {
throw new Error();
}
}(先ほどのデモを見過ごしてしまった場合はこちらのデモをご覧ください。
なぜ useReducer は React Hooks のチートモードなのか
state のアップデートが一つ前や別の state 変数に依存してる場合にエフェクトの依存配列から取り出す方法を学びました。 ですが、次の state を計算するにあたって props が必要な場合はどうでしょう? 例えば、APIが <Counter step={1}> だとしましょう。この場合だと、 props.step を依存配列に入れる以外の手段はないと思いますよね。
いえ、取り出す方法はあります! reducer 自体をコンポーネント内に入れて props を読むようにしたらいいのです:
function Counter({ step }) { const [count, dispatch] = useReducer(reducer, 0);
function reducer(state, action) {
if (action.type === 'tick') {
return state + step; } else {
throw new Error();
}
}
useEffect(() => {
const id = setInterval(() => {
dispatch({ type: 'tick' });
}, 1000);
return () => clearInterval(id);
}, [dispatch]);
return <h1>{count}</h1>;
}このパターンは多少パフォーマンス最適化に影響を及ぼしますが、 reducer 内で props を参照することはできます。(デモはこちら。)
この場合でも、 dispatch は再 render されても不変であることは保証されています。 なので、エフェクトの依存配列から取り除きたい場合は取り除くことが可能です。なぜかというと、エフェクトを再実行することはないからです。
どうして reducer は別の render に属している props を読むことができるの?と思われるでしょう。なぜかと言うと、 dispatch をする時に React はそのアクションだけを覚えて、次の render 時に reducer を呼びます。その時には最新の props がスコープ内に存在しており、エフェクトの中かどうかというのは関係なくなります。
これらの理由から私は useReducer を React のチートモード と呼んでいます。アップデートロジックとそれらを宣言的に記述する表現を分離してくれます。こうすることによって、不必要な依存変数をエフェクトから取り除くことができ、必要最低限の render で済むのです。
エフェクト内に関数を入れる
関数は依存配列に入れる必要がないと思うのはよくある間違いです。例えば、この例はまともに動くように見えます:
function SearchResults() {
const [data, setData] = useState({ hits: [] });
async function fetchData() {
const result = await axios(
'https://hn.algolia.com/api/v1/search?query=react',
);
setData(result.data);
}
useEffect(() => {
fetchData();
}, []); // これでもいい?
// ...(この例 は Robin Wieruch の素晴らしい記事から抜粋しています — 詳しくはこちら!)
先に言っておくと、この例はちゃんと動きます。ですが、ローカル関数を依存配列に含めない一番の問題は、コンポーネントが肥大化していくと全てのケースをハンドリングしているか分からなくなるという点です。
例えば、下記のコードのようにコードが分離されていて、さらにそれぞれの関数が五倍多いと想像して見てください:
function SearchResults() {
// この関数がこれより多いと想像してください
function getFetchUrl() {
return 'https://hn.algolia.com/api/v1/search?query=react';
}
// この関数も、これより多いと想像してください
async function fetchData() {
const result = await axios(getFetchUrl());
setData(result.data);
}
useEffect(() => {
fetchData();
}, []);
// ...
}次に、どちらかの関数に state か prop を用いるとしましょう:
function SearchResults() {
const [query, setQuery] = useState('react');
// この関数がこれより多いと想像してください
function getFetchUrl() {
return 'https://hn.algolia.com/api/v1/search?query=' + query; }
// この関数も、これより多いと想像してください
async function fetchData() {
const result = await axios(getFetchUrl());
setData(result.data);
}
useEffect(() => {
fetchData();
}, []);
// ...
}この場合、もし関数が呼ばれているエフェクトの依存配列の中身をアップデートし忘れると、エフェクトは prop や state からの変更をシンクロできません。それはよくないですね。
ですが、運よくこの問題には簡単な解決方法があります。 もしそれらの関数はエフェクト内でしか呼ばれていないのであれば、直接エフェクト内に移しましょう:
function SearchResults() {
// ...
useEffect(() => {
// 関数定義をエフェクト内に移しました function getFetchUrl() { return 'https://hn.algolia.com/api/v1/search?query=react'; } async function fetchData() { const result = await axios(getFetchUrl()); setData(result.data); }
fetchData();
}, []); // ✅ 依存配列はオッケー
// ...
}(デモはこちら.)
この方法を用いる利点はなんでしょうか?もう依存関係について関数をトラッキングする必要はありません。我々の依存配列は嘘をついていません: 正真正銘、エフェクトはエフェクト外から何も用いてないからです。
もし後ほど getFetchUrl を編集して query の state を用いることがあれば、エフェクトの中で編集しているのに気づくでしょう - そして、 query をエフェクトの依存配列に加える必要があるのもわかるはずです:
function SearchResults() {
const [query, setQuery] = useState('react');
useEffect(() => {
function getFetchUrl() {
return 'https://hn.algolia.com/api/v1/search?query=' + query; }
async function fetchData() {
const result = await axios(getFetchUrl());
setData(result.data);
}
fetchData();
}, [query]); // ✅ 依存配列はオッケー
// ...
}(デモはこちら.)
依存関係を足すことによって、React をなだめるように書くだけではなく、クエリーが変わればデータを再取得するという一連の 理屈が通った フローになります。 useEffect のデザインは、データフローの変更とそれに伴いエフェクトがどのようにシンクロするかを強制的に気づかせてくれます。ユーザーがバグを踏んでからやっと気付いたりする前に。
eslint-plugin-react-hooks プラグインの exhaustive-deps lint ルールのおかげで、エディターに入力すると同時にエフェクトを分析してどの依存関係が欠けているかチェックしてくれます。言い換えると、マシンがコンポーネントのどのデータフロー変更が正しくハンドリングされていないかチェックしてくれます。
素晴らしいですね。
でも、この関数はエフェクト内に入れられない
関数をエフェクト内に移せないことも時折起こるでしょう。例えば、複数のコンポーネント間のエフェクト内で同じ関数を呼んでおり、それをコピペしたくない時など。あるいは、関数自体が prop として渡されたり。
これらの場合はエフェクトの依存関係を無視しても良いのでしょうか?僕は違うと思います。もう一度言いますが、エフェクトは依存関係について嘘をついてはいけません。 スキップするより効率的な解決方法はあります。「関数は変わらない」とよく聞きますが、これは誤解です。この記事を読んでくれたらわかると思いますが、「関数が変わらない」ほど真実から遠い事実はありません。なぜなら、コンポーネント内に定義されている関数は毎 render 時に変わるのですから。
ですが、それはそれで問題を引き起こします。例えば、二つのエフェクトが getFetchUrl を呼ぶとしましょう:
function SearchResults() {
function getFetchUrl(query) {
return 'https://hn.algolia.com/api/v1/search?query=' + query;
}
useEffect(() => {
const url = getFetchUrl('react');
// ... データをフェッチして何かする
}, []); // 🔴 getFetchUrlが依存配列から抜けてる
useEffect(() => {
const url = getFetchUrl('redux');
// ... データをフェッチして何かする
}, []); // 🔴 getFetchUrlが依存配列から抜けてる
// ...
}この場合、 getFetchUrl をどちらかのエフェクト内に定義してしまうと、共通ロジックを使用できなくなるため入れたくないでしょう。
ですが、逆に依存関係に忠実だと、それはそれで問題を起こします。なぜかというと、両方のエフェクトは getFetchUrl に依存してる(そして render ごとに違う)ので、我々の依存配列は全く役に立ちません:
function SearchResults() {
// 🔴 render ごとに全てのエフェクトを再トリガーする function getFetchUrl(query) { return 'https://hn.algolia.com/api/v1/search?query=' + query; }
useEffect(() => {
const url = getFetchUrl('react');
// ... データをフェッチして何かする
}, [getFetchUrl]); // 🚧 依存配列は合ってるが頻繁に変わる
useEffect(() => {
const url = getFetchUrl('redux');
// ... データをフェッチして何かする
}, [getFetchUrl]); // 🚧 依存配列は合ってるが頻繁に変わる
// ...
}簡単な解決方法として、 getFetchUrl を依存配列から抜きたくなるでしょう。ですが、これはあまりお勧めできる解決策ではありません。抜いてしまうと、エフェクトでハンドリングされるべき変更が加わっても分かりづらいからです。このようなことが先ほどお見せした、インターバルが更新されないようなバグを引き起こすのです。
代わりとして、シンプルな二つの解決法があります。
まず、もし関数がコンポーネントスコープから何一つ使用していないならば、関数をコンポーネント外にホイスティングして自由にエフェクト内で使う方法:
// ✅ データフローに影響されないfunction getFetchUrl(query) { return 'https://hn.algolia.com/api/v1/search?query=' + query;}
function SearchResults() {
useEffect(() => {
const url = getFetchUrl('react');
// ... データをフェッチして何かする
}, []); // ✅ 依存配列もオッケー
useEffect(() => {
const url = getFetchUrl('redux');
// ... データをフェッチして何かする
}, []); // ✅ 依存配列もオッケー
// ...
}render スコープに関数がそもそもないので、データフローに影響されず依存配列に入れる必要もありません。間違って props や state に依存してしまう、ということも起きません。
もう一つの方法として、 useCallback フックを使用することもできます:
function SearchResults() {
// ✅ 依存配列が同じだと関数の整合性が担保される const getFetchUrl = useCallback((query) => { return 'https://hn.algolia.com/api/v1/search?query=' + query; }, []); // ✅ Callback deps are OK
useEffect(() => {
const url = getFetchUrl('react');
// ... データをフェッチして何かする
}, [getFetchUrl]); // ✅ 依存配列もオッケー
useEffect(() => {
const url = getFetchUrl('redux');
// ... データをフェッチして何かする
}, [getFetchUrl]); // ✅ 依存配列もオッケー
// ...
}useCallback が何をしてるかというと、依存チェックのレイヤーを追加しているのです。別の軸で問題を解決してるのです - 関数の依存チェックを避けるのではなく、関数自体を依存関係に変更があったら時だけ変えているのです。
なぜこのアプローチが有効的か見てみましょう。以前は、我々の例は二つの検索結果を表示してました(react と redux の検索クエリ)。ですが、任意のクエリを受け取るためインプットを追加するとしましょう。要するに、 query を引数で受け取るのではなく、 getFetchUrl はローカルの state からクエリを受け取ります。
query の依存配列チェックがないことにすぐ気づけます:
function SearchResults() {
const [query, setQuery] = useState('react');
const getFetchUrl = useCallback(() => { // クエリの引数がない
return 'https://hn.algolia.com/api/v1/search?query=' + query;
}, []); // 🔴 query が依存配列から抜けてる // ...
}query を依存配列に入れるよう useCallback を修正すると、 getFetchUrl が依存配列に含まれる全てのエフェクトは query が変更した場合だけ再実行されます:
function SearchResults() {
const [query, setQuery] = useState('react');
// ✅ 依存配列が同じだと関数の整合性が担保される const getFetchUrl = useCallback(() => { return 'https://hn.algolia.com/api/v1/search?query=' + query; }, [query]); // ✅ Callback deps are OK
useEffect(() => {
const url = getFetchUrl();
// ... データをフェッチして何かする
}, [getFetchUrl]); // ✅ 依存配列もオッケー
// ...
}useCallback のおかげで、 query が同じであれば getFetchUrl も同じであることが担保されるので、エフェクトは再実行されません。ですが query が変わると getFetchUrl も変わるのでデータを再取得しにいきます。エクセルのスプレッドシートでセルの中を変えると他のセルが自動的に再計算するイメージと似ています。
これらはデータフローとシンクロというマインドセットを掛け持った結果にすぎません。親コンポーネントから関数を渡す場合でも同じ解決方法が使えます:
function Parent() {
const [query, setQuery] = useState('react');
// ✅ 依存配列が同じだと関数の整合性が担保される const fetchData = useCallback(() => { const url = 'https://hn.algolia.com/api/v1/search?query=' + query; // ... データをフェッチして返す }, [query]); // ✅ Callback の依存配列はオッケー
return <Child fetchData={fetchData} />
}
function Child({ fetchData }) {
let [data, setData] = useState(null);
useEffect(() => {
fetchData().then(setData);
}, [fetchData]); // ✅ 依存配列はオッケー
// ...
} fetchData は親コンポーネントの query が変わるまで同じであることが担保されているので、子コンポーネントは必要になるまでデータを取得しにいきません。
関数はデータフローの一部なのか
興味深いのは、先ほど紹介したパターンはクラスの場合だとうまく動かなく、エフェクトとライフサイクルパラダイムの違いをはっきりと見せてくれます。この例をみてみてください:
class Parent extends Component {
state = {
query: 'react'
};
fetchData = () => { const url = 'https://hn.algolia.com/api/v1/search?query=' + this.state.query; // ... データをフェッチして何かする }; render() {
return <Child fetchData={this.fetchData} />;
}
}
class Child extends Component {
state = {
data: null
};
componentDidMount() { this.props.fetchData(); } render() {
// ...
}
}今こう思うでしょう:「ねぇダン、useEffect は componentDidMount と componentDidUpdate が一緒になっているだけなの知ってるから!これ以上ごまかしても無駄!」 ですがこれは componentDidUpdate でも動きません:
class Child extends Component {
state = {
data: null
};
componentDidMount() {
this.props.fetchData();
}
componentDidUpdate(prevProps) { // 🔴 この比較は正にはならない if (this.props.fetchData !== prevProps.fetchData) { this.props.fetchData(); } } render() {
// ...
}
}fetchData はクラスメソッドなので、これは当たり前です(それかクラスプロパティー - どっちでもいいけど)。state の変更があったからといって変わりません。なので、 this.props.fetchData は prevProps.fetchData と同じであるため再フェッチされません。なら、条件分岐を消したらどうでしょう:
componentDidUpdate(prevProps) {
this.props.fetchData();
}ですが、こう記述すると 毎 render 時にフェッチしにいきます。(アニメーションをツリーの上に追加してあげると分かります。)ならば、特定のクエリに bind するのはどうでしょう:
render() {
return <Child fetchData={this.fetchData.bind(this, this.state.query)} />;
}ですが query が変わってなくても this.props.fetchData !== prevProps.fetchData は常に正です!なのでまだ 毎 render 時にフェッチしにいきます。
唯一の解決方法として、 query 自体を子コンポーネントに渡すしかありません。子コンポーネントは query を実際に使うことはないですが、変更を検知してフェッチを行うことができます:
class Parent extends Component {
state = {
query: 'react'
};
fetchData = () => {
const url = 'https://hn.algolia.com/api/v1/search?query=' + this.state.query;
// ... データをフェッチして何かする
};
render() {
return <Child fetchData={this.fetchData} query={this.state.query} />; }
}
class Child extends Component {
state = {
data: null
};
componentDidMount() {
this.props.fetchData();
}
componentDidUpdate(prevProps) {
if (this.props.query !== prevProps.query) { this.props.fetchData(); } }
render() {
// ...
}
}React に関わって数年、もう不必要な props を子に渡して親コンポーネントのエンキャプスレーションを壊す行為(そして数週間後になぜやる必要があったのかに気づく)に慣れてしまいました。
クラスの場合、関数 props 自体はデータフローの一部ではありません。 mutable な this の値が存在するので関数の整合性が担保できないからです。なので、関数だけ渡したくても無駄なデータを渡して diff をとる必要が出てくるのです。this.props.fetchData がどの state に依存していて、 state がどのタイミングで変更されたを知る余地がありません。
useCallback により、関数はデータフローに参加することができます。 もし関数のインプットが変更されれば関数自体も変更されたと検知でき、インプットが変更されてなければ同じであることが分かります。useCallback のおかげで、 props.fetchData などの props の変更も、自動的に子へ伝わっていきます。
useMemo も同じようなことを複雑なオブジェクトに適用してくれます:
function ColorPicker() {
// 子の shallow equality check にちゃんと通ります
// color が変わらない限り
const [color, setColor] = useState('pink');
const style = useMemo(() => ({ color }), [color]);
return <Child style={style} />;
}useCallback を巻き散らかすのはあまりよくないことを強調したいです。 良いエスケープハッチで、関数が子に渡されて子の中のエフェクトで呼ばれてる場合などではとても役に立ちます。それか子コンポーネントのメモ化を崩したくない時など。ですが、Hooks はそもそも 関数を props として渡す行為をあまり推薦していません。
上記の例の場合、個人的には fetchData をエフェクト内に定義するか(そしてそれ自体をカスタムフックとして抽出できる)、トップレベルインポートにする方を好みます。エフェクトをシンプルに保ちたいのに、コールバックがあると複雑化してしまいます(例えば、 props.onComplete のコールバックがリクエスト中に変わったりとか)。クラスでの振る舞いは再現できますが、レースコンディションは解決されません。
レースコンディションについて
典型的なデータフェッチングをするクラスコンポーネントは、これに似てるでしょう:
class Article extends Component {
state = {
article: null
};
componentDidMount() {
this.fetchData(this.props.id);
}
async fetchData(id) {
const article = await API.fetchArticle(id);
this.setState({ article });
}
// ...
}みなさんご存知の通り、このコードはバグを引き起こします。なぜなら、アップデートをハンドリングしていないから。なので、もう一つ典型的なクラスコンポーネントとして、次のような例をよく見るでしょう:
class Article extends Component {
state = {
article: null
};
componentDidMount() {
this.fetchData(this.props.id);
}
componentDidUpdate(prevProps) { if (prevProps.id !== this.props.id) { this.fetchData(this.props.id); } } async fetchData(id) {
const article = await API.fetchArticle(id);
this.setState({ article });
}
// ...
}いいですね。ですが、まだバグを引き起こせます。なぜなら、リクエストの順番が担保されていないからです。例えば、 {id: 10} をフェッチしていて {id: 20} に変更してそのリクエストが先に返ってきた場合、最初にリクエストして後から終わった処理は state を不正に上書きしてしまいます。
これがレースコンディションです。そして、これは async / await を含むコード(結果が戻るまで待つことが前提)とトップダウンなデータフロー(非同期関数の処理中に state や props が代わり得る)を混ぜたコードでよく起こる現象です。
エフェクトはこの問題を解決するものではありませんが、 非同期関数をエフェクトに渡そうとすると注意してくれます。(どのような問題に直面するかもっとはっきりさせるように注意文言を改善する必要がありますが。)
もし非同期処理がキャンセル可能ならば、cleanup 関数で非同期リクエストをキャンセルできるので、解決できますね。
あるいは、boolean を用いてトラッキングするというその場しのぎの解決方法もあります:
function Article({ id }) {
const [article, setArticle] = useState(null);
useEffect(() => {
let didCancel = false;
async function fetchData() {
const article = await API.fetchArticle(id);
if (!didCancel) { setArticle(article);
}
}
fetchData();
return () => { didCancel = true; }; }, [id]);
// ...
}具体的にどのようにエラーハンドリングやローディングして、カスタムフックに抽出できるかに興味がある人はこちらの記事を読むことをお勧めします。
ハードルをあげる
クラスのライフサイクルマインドセットだと、render で出力されるものと副作用は異なってみえます。UIのレンダリングは props や state ドリブンで引き起こされており整合性は取れているのは保証されてますが、副作用は違います。これがバグが起こる理由です。
ですが、 useEffect のマインドセットだと、全てデフォルトでシンクロされています。副作用は React のデータフローの一部となります。useEffect で起こる処理を上手くやれば、あなたのコンポーネントはエッジケースにより対応しやすくなります。
しかし、正確にするということは、より労力を費やす必要があります。これはかなり面倒です。シンクロを軸に置いて書くコードは、レンダリングとはシンクロしない一度限りの副作用の発火させるコードより難しいのは当たり前です。
もしあなたは useEffect を主要ツールとして使用しているなら、少し心配です。ですが、 useEffect は低レイヤーのブロックです。まだ Hooks が出て間もないので、特にチュートリアルなどでみんな低レイヤーであるものを乱用しています。時間が立つにつれ、コミュニティーは高レベルな Hooks に移っていくでしょう。
多種多様なアプリが、認証ロジックをカブセル化した useFetch や theme context を使用する useTheme などの Hooks を作成してるのを見てきました。これらのツールボックスが一度出来上がると、そこまで useEffect を使用することは無くなってくるでしょう。ですが、 useEffect がもたらす強靭性は、それらを上に作成される Hooks 全てが恩恵を受けられるでしょう。
これまでに、 useEffect は主にデータフェッチング用として使われていました。ですが、データフェッチングは正確にはシンクロ問題ではありません。データフェッチング用の依存配列は主に [] なので、より明確です。そもそも何をシンクロしているのでしょうか?
将来的に、データフェッチング用の Suspense が React にレンダリングを非同期処理中は中断するといったサポートをします。
Suspense が今後データフェッチングケースをハンドリングしていくにつれ、useEffect は表舞台からフェードアウトして、本当に props や state を何かしらの副作用にシンクロしたい時だけに使われると思います。データフェッチングとは違い、このようなケースは自然に対応できます。なぜなら、そのために作られたからです。ですがSuspense がデータフェッチングケースをハンドリングするまでは、これのようなカスタムフックを用いてデータフェッチングをすると良いでしょう。
終わりに
あなたはもう私が知ってるエフェクトの全てを知ってるはずなので、一度最初のTLDRに戻ってみてください。ちゃんと伝わりますでしょうか?抜け漏れとかないですか?
ツイッターで意見聞きたいです!読んでいただきありがとうございました。